Bonjour j’aurais encore une petite question concernant cette fois-ci les données manquantes.
Mes questions sont les suivantes : existe t-il un cut off consensuel au delà duquel si l’on a plus de x% de valeurs manquantes, il n’est pas recommandé d’analyser les données ? Quelle est la différence entre une méthode de délétion listwise et pairwise ? (je n’ai pas compris à quoi cela correspondait en pratique, et du coup je n’arrive pas à déterminer dans quel cas je me situe). Y a t-il des astuces pour déterminer si nos données manquantes ne sont pas liées au hasard ?
Dans mon étude je décrivais les modalités d’utilisation de la rtms incluant les 26 premiers patients incidents. Le fait de ne pas exclure les sujets avec données manquantes apporte des informations utiles pour l’amélioration de la pratique mais complique la description / évaluation de l’efficacité du traitement. Bien sûr comme vous l’avez précisé l’absence de groupe contrôle ne permet pas de dire si les améliorations observées sont liées à la rtms ou à des facteurs confondants, mais je trouvais qu’il était intéressant de donner un aperçu des taux de réponses obtenus (car on avait un profil de patients avec de nombreux facteurs de risque de résistance thérapeutique; le taux de réponse très faible observé n’est donc pas étonnant mais il est tout de même très très largement inférieur à ce qui est observé dans la littérature).
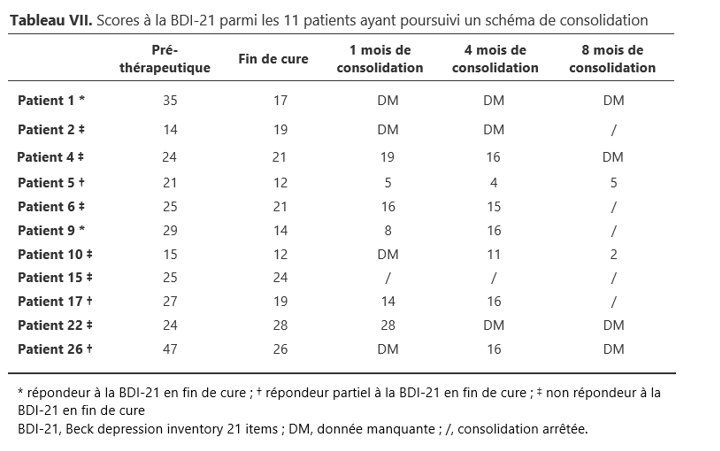
Le taux d’évaluations manquantes avant traitement et en fin de cure est de 34,7%. Ce qui fait que je n’ai analysé l’efficacité du traitement que pour 15 des 26 patients inclus (-3 patients ayant arrêté la cure du fait d’effets indésirables). Est ce une erreur d’avoir fait cette analyse compte tenu du taux élevé que cela représente ? Et d’avoir une méthode de gestion par analyse des cas complets ? (je l’ai choisi car ça me semblait plus honnête qu’une méthode d’imputation, que mon étude était à visée descriptive et que ça me semblait compliqué à mon niveau de savoir faire une méthode d’imputation). Mais j’ai vu qu’il était inexact de le faire si les données manquantes n’étaient pas liées au hasard. Comment peut-on savoir si ces données manquantes sont liées ou non au hasard ? (dans mon cas les données manquantes concernaient majoritairement les échelles psychométriques, notamment celles que le psychiatre était censées remplir à différents temps du suivi du patient. Mais je n’ai pas de moyen de savoir si cela est du à un oubli / manque de temps ou si cela est lié à l’état clinique du patient : peut être allait-il mieux et le psychiatre n’a pas jugé bon de remplir l’échelle, ce qui ressort de façon la plus flagrante c’est que les échelles sont bien passées pendant la cure (mais pas pour le traitement d’entretien) pour les 10 premiers patients pris en charge par le chu, mais qu’après elles tendent à être d’avantage manquantes). Je me suis contentée de présenter dans un tableau le pourcentage de chaque évaluation psychométrique effectivement réalisée aux 6 temps d’évaluations (en précisant pour chaque temps l’effectif de patients poursuivant encore le traitement). Est ce qu’il existerait un moyen graphique permettant de présenter les données manquantes pour les principales échelles, en fonction du temps et de certaines autres variables (comme l’inclusion dans un autre protocole, la venue ou non à la consultation, l’année de traitement) ? ou est ce que cela serait trop compliqué vu le nombre de variables et il vaut mieux décrire par écrit les situations dans lesquelles les données étaient manquantes ? Est ce une erreur d’aborder une interprétation de l’efficacité du traitement (en terme de taux de réponse) dans la discussion compte tenu de tous les biais que cela implique ?
Merci par avance pour vos retours et votre aide précieuse