Bonjour,
Tout d’abord je vous remercie grandement pour la création de ce site et l’aide que vous fournissez.
Je dois soutenir ma thèse très prochainement, et la personne qui m’encadre ne sait pas faire les statistiques nécessaires pour notre étude.
J’ai essayé de faire les analyses avec le site pvalue io mais je ne suis pas sûr que cela soit correct…
Dans cette étude, nous cherchons à identifier un potentiel impact de la fragilité en préopératoire d’une chirurgie (en l’occurrence chirurgie cardiaque) sur l’évolution qualité de vie post opératoire des patients.
Pour cela nous disposons de données de fragilité pré-opératoire (Cotée, de 1 à 4, selon 4 groupes possibles, du sujet le plus robuste au sujet fragile, avec la catégorie 4 étant considérée comme fragile) ainsi que des données de qualité de vie (synthétisées par un index compris entre -0.530 et 1) en pré opératoire et en post opératoire (à 3 mois).
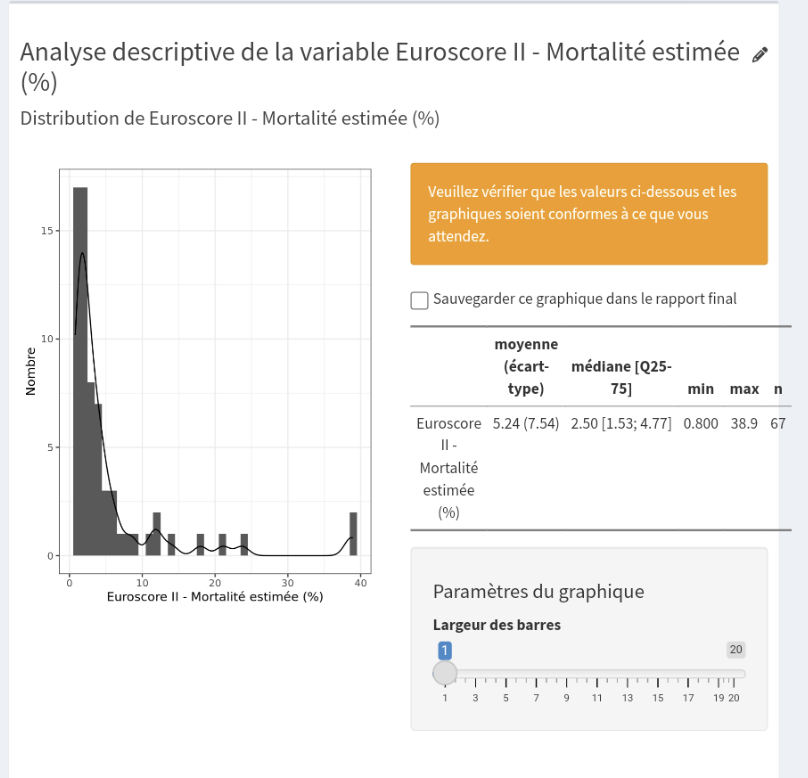
Nous disposons des données de 67 patients, avec 4 valeurs manquantes pour la qualité de vie post opératoire et une prévalence de la fragilité à 15%, soit 10 sujets.
Pour rentrer les données dans l’outil, nous avons rentré comme variable explicative la fragilité (Oui ou Non) et comme variable expliquée la différence obtenue entre les valeurs des index post et préopératoires de qualités de vie. Nous souhaitions également faire une analyse multivariée avec un ajustement sur une donnée préopératoire de prédiction de mortalité (score de 0 à 100).
Le logiciel indique avoir réalisé une régression linéaire univariée et multivariée avec ajustement sur le score de mortalité, avec des résultats qui semblent intéressants pour nous, avec une moyenne des différences des index de qualité de vie significativement différente chez les sujets fragiles.
Je me pose des questions sur les outils statistiques utilisés :
- Est-il pertinent de réaliser une régression linéaire avec une variable explicative qualitative Oui/Non ?
- Utiliser comme variable la différence entre les index post et pré opératoires est-il juste ?
Nous savons d’après la littérature précédente et d’après nos analyses descriptives que les patients de groupe 1 ont une faible baisse de l’index, que les patients groupe 2 et 3 ont une augmentation alors que les patients de groupe 4 (fragile) ont une franche baisse de l’index de qualité de vie.
- Est-il plus intéressant d’effectuer nos analyses selon la fragilité Oui/Non ? ou selon la classe de fragilité 1,2,3 ou 4 ? (avec une évolution qui a priori ne semble pas linéaire)
- Quel test semble le plus pertinent dans ce cas de figure ?
Quand nous réalisons une analyse dite ‹ descriptive ›, pvalue io indique avoir réalisé un test non paramétrique (de Mann-Whitney) avec un rang moyen de ‹ Différence d’index › significativement différent suivant la Fragilité préopératoire (Oui/Non)
- Devons nous réaliser d’autres analyses ou celles ci sont suffisantes ? Est il possible d’ajouter une variable pour réaliser une analyse multivariée en ajustant sur le score prédictif de mortalité ?
Par avance, un grand merci pour votre aide bienveillante
Cordialement
Bonjour,
Voici mes réponses :
- régression linéaire pour une variable explicative qualitative : aucun problème, le terme « linéaire » implique une variable expliquée quantitative. Peu importe le type de variable explicative. Dans une régression linéaire multiple (avec ajustements) il est même possible d’utiliser des variables de différentes natures (quali/quanti)
- le delta post-pré est tout à fait classique.
- votre variable fragilité n’étant pas linéairement associée à la qualité de vie, vous ne pourrez pas la traiter comme une variable quantitative. Comme il n’y a pa de tendance, même non linéaire (les groupes 1 et 4 sont similaires), vous ne pourrez pas non plus traiter votre variable comme étant ordinale. Reste donc la solution de traiter celle-ci de façon qualitative. Peut-être effectuer vos comparaisons en 2 temps ? → 1 vs [2+3] puis 4 vs [2+3].
- si vous restez en analyse simple (univariée), un simple Chi2 ou Fisher fera l’affaire (1 vs [2+3] puis 4 vs [2+3]). S’il ne ressort rien d’intéresant vous pouvez également simplifier l’analyse en ne réalisant qu’un unique Chi2 d’homogénéité 1 vs [2+3] vs 4 (à la différence du cas précédent, vous n’obtiendrez qu’une seule p-value → pratique pour résumer les situations où rien n’est significatif en 1 seul test)
Si vous souhaitez intégrer la fragilité dans votre régression linéaire attention ! Vous devrez définir l’un de vos groupes comme référence. Les coefficients Beta seront alors exprimés par rapport à cette référence. Vous pourriez par exemple définir le groupe [2+3] comme référence et obtenir les coefficients Beta pour les groupes 1 et 4. A voir si cela fait sens dans votre contexte ou non
- analyse descriptive de p-value : une analyse descriptive sous-entend normalement l’absence de test statistique (par opposition à une phase analytique).
- faut-il réaliser d’autres tests ? cela dépend des objectifs fixés. Si vous souhaitez savoir si la fragilité diffère selon la qualité de vie → vous avez déjà la réponse. Cherchez-vous autre chose ? PS : si cet index suit une loi normale, un test de Student est peut-être plus approprié. Celui-ci a l’avantage de permettre d’exprimer la différence moyenne (d’index) entre vos 2 froupes (fragilité oui/non) avec son IC95. C’est une statistique simple qui vous permettra d’exprimer clairement la différence et d’en juger la pertinence clinique. Utiliser le Mann-Witney suppose une distribution non paramétrique, et il serait donc illogique de mentionner la différence moyenne avec ce test.
Pour votre dernière question quant à l’ajustement du résultat précédent sur le score prédictif de mortalité, je ne suis pas sur de comprendre. Que cherchez vous à faire ?
- prédire la fragilité (oui/non) en fonction de l’index de qualité de vie ET du score prédictif de mortalité ?
- prédire l’index de qualité de vie en fonction de la fragilité (oui/non) ET du score prédictif de mortalité ?
- autre ?
Bonjour,
Un très grand merci pour ces réponses et ces éclaircissements.
Dans mon analyse principale, je souhaiterais comparer les classes [1+2+3] vs [4], il est plus pertinent cliniquement de ne pas séparer 1 et 2, et je pense que l’effet négatif de la classe 1 étant peu important, les résultats resteront en défaveur de la classe 4.
Je souhaiterais montrer que la différence de qualité de vie est plus importante selon la présence d’une fragilité préopératoire (Oui/Non)
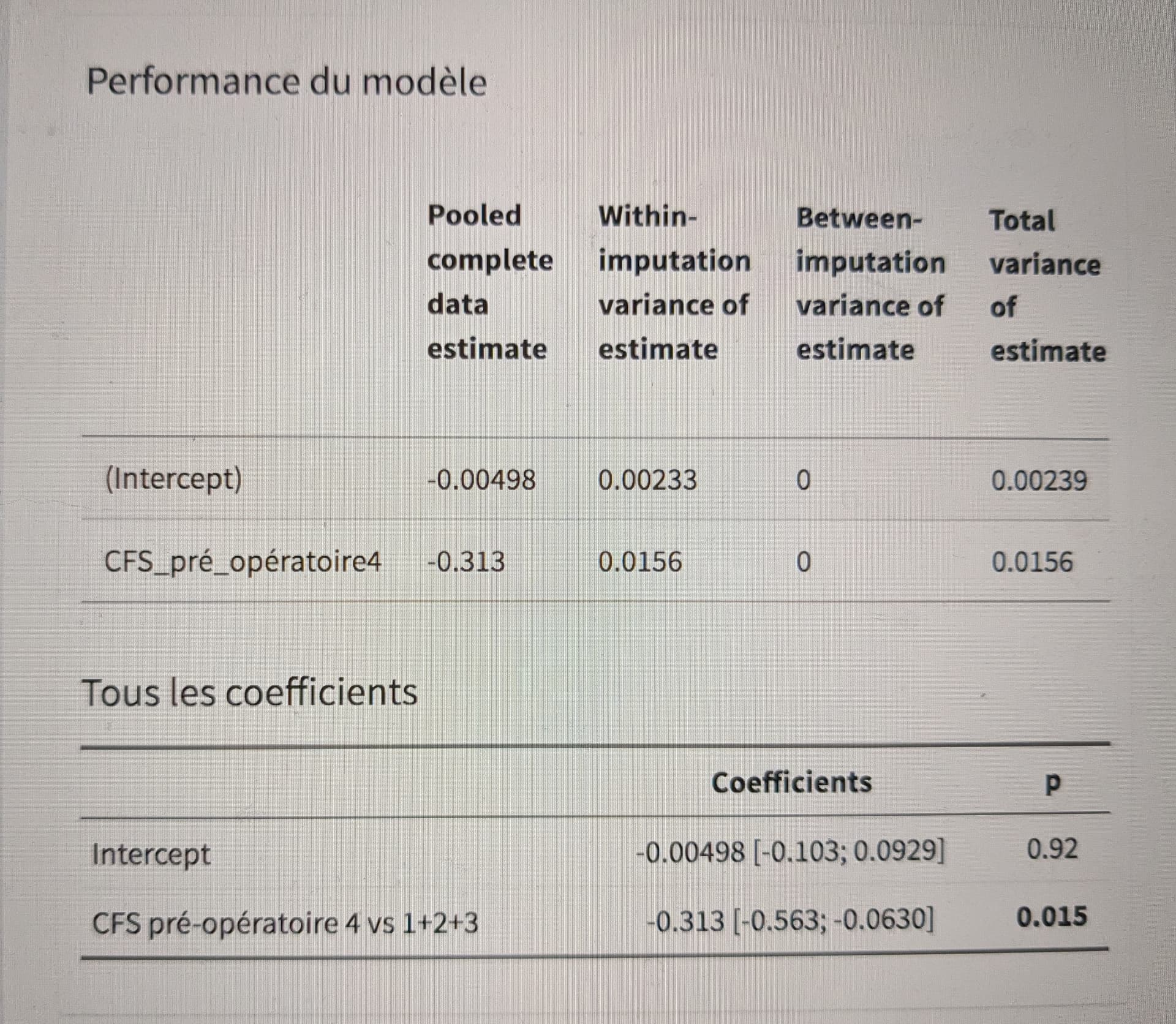
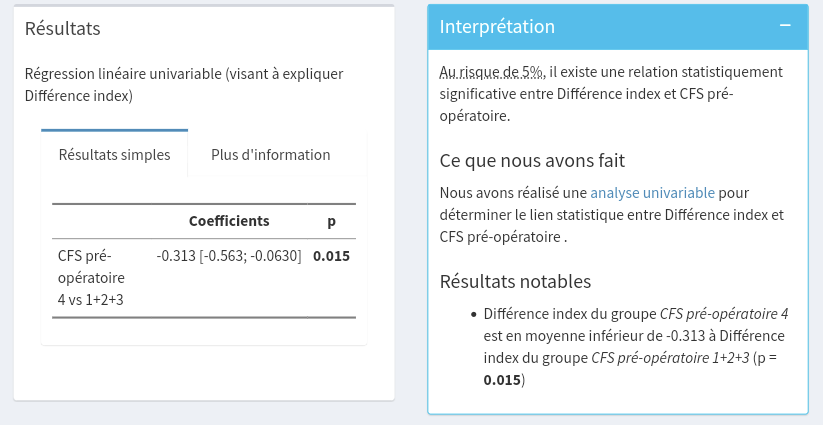
- Dans ce cas, réaliser une régression linéaire avec une référence définie comme [1+2+3] vs [4] est-il intéressant ?
Avec p value j’obtiens, une différence moyenne plus importante dans le groupe 4 avec un résultat significatif.
Même si mon effectif est faible (n=67 avec 4 données manquantes) et qu’il n’y a que 15% de patient du groupe 4 cela reste pertinent ?
- Est-il plus intéressant de réaliser un test de Student, comme vous l’avez proposé ?
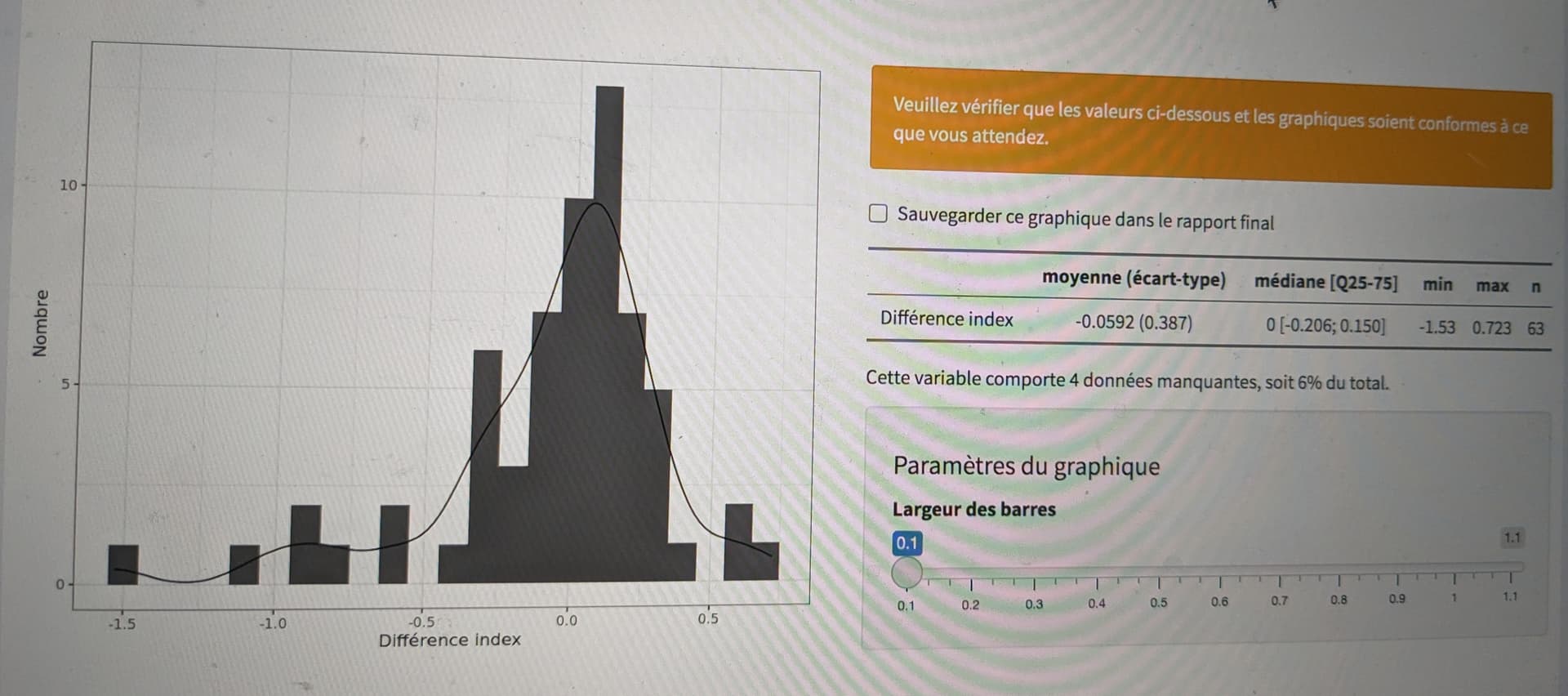
Sur les courbes avec la distribution de l’index, il semble suivre une loi normale, dois je réaliser un test supplémentaire ou est ce que je peux me contenter de cette aspect de la distribution ?
- pour ma derniere question, afin de prédire une dégradation de la qualité de vie selon la présence d’une fragilité, j’aurais souhaité ‹ ajuster › mes résultats sur le score prédictif de mortalité, pour trouver un effet propre de la fragilité sur la détérioration de la qualité, non uniquement lié a l’effet du score prédictif de mortalité…
Mais peut être que ce sont des analyses un peu trop complexes a réaliser ?
Encore un grand merci par avance
Votre 3 questions sont liées. D’après votre histogramme, un test de Student me semble raisonnable mais la régression linéaire est tout aussi valable pour [1+2+3] vs [4].
Cependant la régression linéaire vous permettra d’ajuster alors que le Student non.
Pour ajuster votre modèle de régression sur le score prédictif de mortalité il vous suffit d’ajouter ce score comme variable prédictive en plus de la fragilité.
Si vous partez dans cette voie, pensez bien à d’abord explorer les résultats en univarié pour vos 2 facteurs PUIS à réaliser l’analyse ajustée. Regardez alors si les résultats son concordants entre l’analyse simple et l’ajustement. Cela vous aidera à débusquer un éventuel facteur de confusion.
Un immense merci pour vos éclaircissements qui m’ont été d’une grande aide.
- afin d’être sûr d’avoir bien compris et pour essayer de résumer les résultats obtenus :
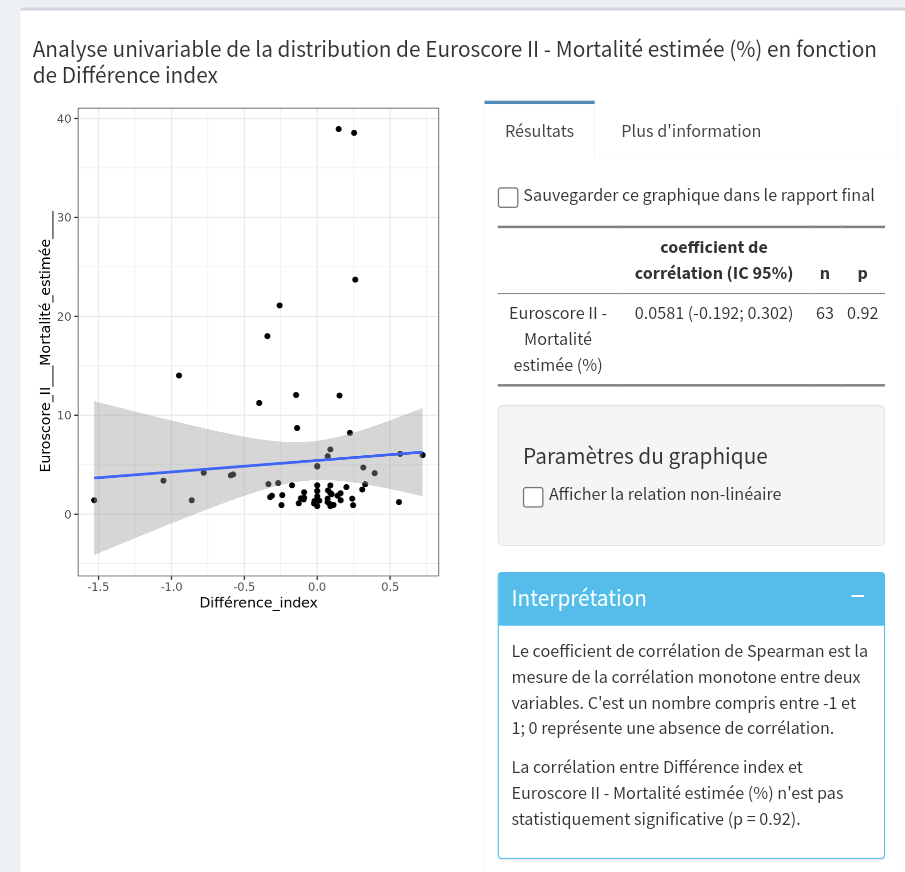
Il y a une différence significative en régression linéaire univariée pour la Fragilité mais pas pour le score de mortalité.
En analyse multivariée : en ajustant sur le score de mortalité les résultats donnent toujours une différence significative selon la fragilité, donc le score de mortalité n’est pas un facteur de confusion ?
Cette ajustement est très intéressant pour l’analyse des résultats car nous avons alloué un index de qualité de vie (pire dégradation possible) aux patients décédés au cours du suivi.
Ainsi nous pouvons conclure que la fragilité est associée a une dégradation de la qualité de vie et que cette dégradation n’est pas (ou pas uniquement) dûe à une ‹ surmortalité prévisible › dans le groupe fragile ? Est ce exact ?
- et si je peux me permettre une dernière question concernant les commentaires de l’analyse de pvalue :
Est ce que l’utilisation d’un bootstrap pour les intervalles de confiance et les p value est dûe au fait que les résultats du score de mortalité ne suivent pas une loi normale ?
Par avance, un très grand merci
Un très grand merci pour toutes ces explications
Vous m’avez beaucoup aidé dans mes analyses et je vous en suis très reconnaissant.
Merci d’avoir créé une telle plateforme, le soutien fourni est très précieux !
Ce fut un plaisir ! N’hésitez pas à communiquer sur l’existence du forum